 今回は、多数の海外のソフトウェア製品の日本国内での販売とサポート担う当社にとっても日常的な話題の一つである「パッチ」について取り上げます。
今回は、多数の海外のソフトウェア製品の日本国内での販売とサポート担う当社にとっても日常的な話題の一つである「パッチ」について取り上げます。
開発会社が提供する製品について、世界中のユーザーから寄せられる不具合情報や改善リクエストを反映した、最新の状態を維持していただくことは、パッケージ製品のメリットを活用いただく意味でも基本的には推奨されています。
一方で、Microsoft社のWindows Server製品向けのパッチですら、次のような状況が発生したことが専門メディアを中心に報じられました。
今年8月13日にリリースされたWindows Server 2019を含むWindows向けのセキュリティ更新プログラム「KB5041578」の適用後、一部の企業ユーザーにおいてパフォーマンス低下やシステムの遅延が報告された。
主な症状としては、CPU使用率の増加やディスク使用率の上昇、Cryptographic Services(CryptSVC)が起動しないといった問題が確認されている。
このKB5041578は、以下のようなセキュリティ課題に対応するための重要なアップデートとされていた
特に、ウイルス対策ソフトウェアがシステムフォルダをスキャンする際に、これらの問題が発生するケースが多いとされ、問題は企業のサーバーOS環境でより多く報告された
- プロセス ライト (PPL) と呼ばれるWindows OSの保護メカニズムのすり抜けを防止
- 脆弱なドライバーのブロックリスト更新 により、これらのドライバーを利用した攻撃からの防御を強化
- Secure Boot Advanced Targeting (SBAT) により、LinuxとWindowsのデュアルブート環境で古い脆弱なLinuxブートローダーが実行されないように保護
- CVE-2024-37968 という脆弱性への対応を通じて、Windows ServerがDNSサーバーとして動作する場合のセキュリティを強化
この問題は 8月21日 にMicrosoftによって最初に報告され、既知の問題のロールバック(KIR)による一時的な対策がアナウンスされ、その後、9月10日 にリリースされた最新の更新プログラム(KB5043050)でKIRの設定なしで問題が解決されるようになった。
ソフトウェア製品の不具合の対応や、セキュリティ上の脆弱性を解消するためのセキュリティパッチでも、その適用は多くのお客様企業で躊躇されることは珍しくありませんが、今回例に挙げたようなパッチ適用による不具合発生の可能性は、その大きな理由の一つと言えます。
サイバー侵害手口の多くに脆弱性が関わっているとは言うが
よく知られていることですが、多数のサイバー侵害で脆弱性が関わっていると言われています。
例えば、Verizonの2024年データ侵害調査報告書(DBIR)*1は、サイバー攻撃における脆弱性の悪用が急増しており、特に脆弱性が侵害の初期段階で利用されるケースが180%増加したことが強調され、ランサムウェアや脅迫技術の拡大に伴う形で脆弱性の悪用も3倍増加したとしています。
また、サプライチェーン攻撃が急増しており、ソフトウェア依存やサードパーティの脆弱性が主な要因として挙げられ、90%に達しているとも報告しています。
一方で、例えばWindows Serverの脆弱性は2023年の1年間で558件*2報告され、「わかっちゃいるけど対応しきれない」のもパッチ適用という仕事の一面と言えます。
ユーザーや業務に影響するサーバーOSへのパッチ適用は、冒頭のWindows Serverのパッチ適用での不具合のような障害発生を避けるため、まずは検証用環境でパッチ適用をして問題が無いことを確認してから本番用のサーバーに適用するという段階をとることが多くの企業で行われていますが、これには当然、相応の工数が発生します。
また、種類にもよりますが、パッチの適用はサーバーOSの再起動が必要な場合があり、稼働するアプリケーションの種類によってはOSが起動しすべてのサービスが開始するまで、15分程度の時間がかかる場合もあり、システムによってはもっと時間がかかるケースもあるかも知れません。
そうなると、業務が稼働する営業時間内でのパッチ適用は難しいため、担当の方が休日出勤して対応されるケースも少なくなく、これは労務上の課題にも繋がります。
パッチ適用時も含めてアプリケーションを継続稼働させるには
さて、停止させるわけにはいかない、ミッションクリティカルなサービスを継続稼働させるため、これまで多様な技術が導入されてきました。
こうした技術の中でも先端的なソリューションを応用することで、パッチ適用時でもサービスを継続利用できる方法があります。
サーバー環境の障害対策は、古典的なバックアップとレストアから、データの同期やフェイルオーバーといった形態に発展してきましたが、先端的なソリューションを使用すると、アプリケーションレベルでの高可用性の達成を実現できます。
下図は、こうした障害対策の手法の中で、アプリケーションレベルでの高可用性の位置づけを概念図として表しています。
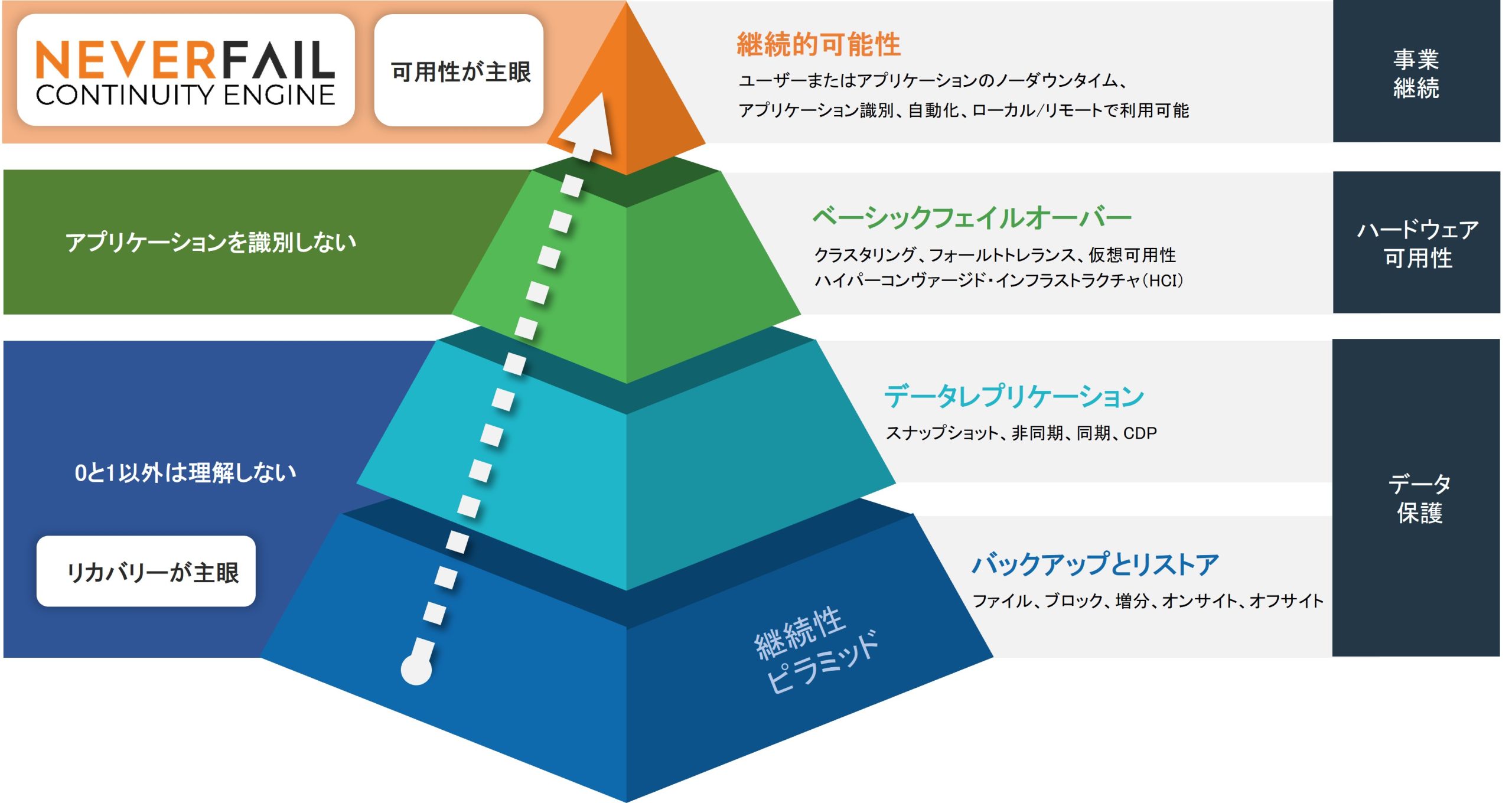
古典的なバックアップとレストアから進化している継続性向上の仕組み
例えばNeverFail社のNeverfail Continuity Engine(CE)は、アプリケーションの継続的な可用性の実現を目的としたソリューションですが、次のことを実現できます。
- 対象サーバーのOS環境はもちろん、アプリケーションサービスのレベルの障害に反応して自動切替
- 数十秒で完璧な精度のスイッチオーバ/フェイルオーバを実現
- 物理、仮想、クラウド等、多様な組み合わせに対応
- 問題解決後のスイッチバック/フェイルバックも容易に実現
この仕組みをパッチ適用時のサービスの継続稼働にどう活かせるでしょうか。
下図はCEを利用して、プライマリ、セカンダリ、さらに場合によりターシャリをLAN/WAN経由でリアルタイム同期させるパターンのイメージで、それぞれのケースで青いサーバーが、その時点でプライマリとして動作していることを表します。
緑のサーバーは待機系で、セカンダリやターシャリとして稼働していますが、これらのサーバーへの変更の影響は、プライマリで稼働している業務に影響を与えません。
つまり待機系にパッチ適用などの変更を加え、必要によりOSを再起動して、さらに必要なサービスが稼働するのを見極める時間を充分にとることができます。
準備ができ次第、作業が終わったサーバーを管理コンソール上の容易な操作でプライマリに切り替えることにより、運用を継続できます。
またこの仕組みでは、プライマリに対してセカンダリやターシャリは「クローン」であるため常に同一の構成であり、一般的な、検証環境を本番機に合わせて維持するといった労力を使うことなくパッチの検証環境としての有効性が確保できるメリットもあります。
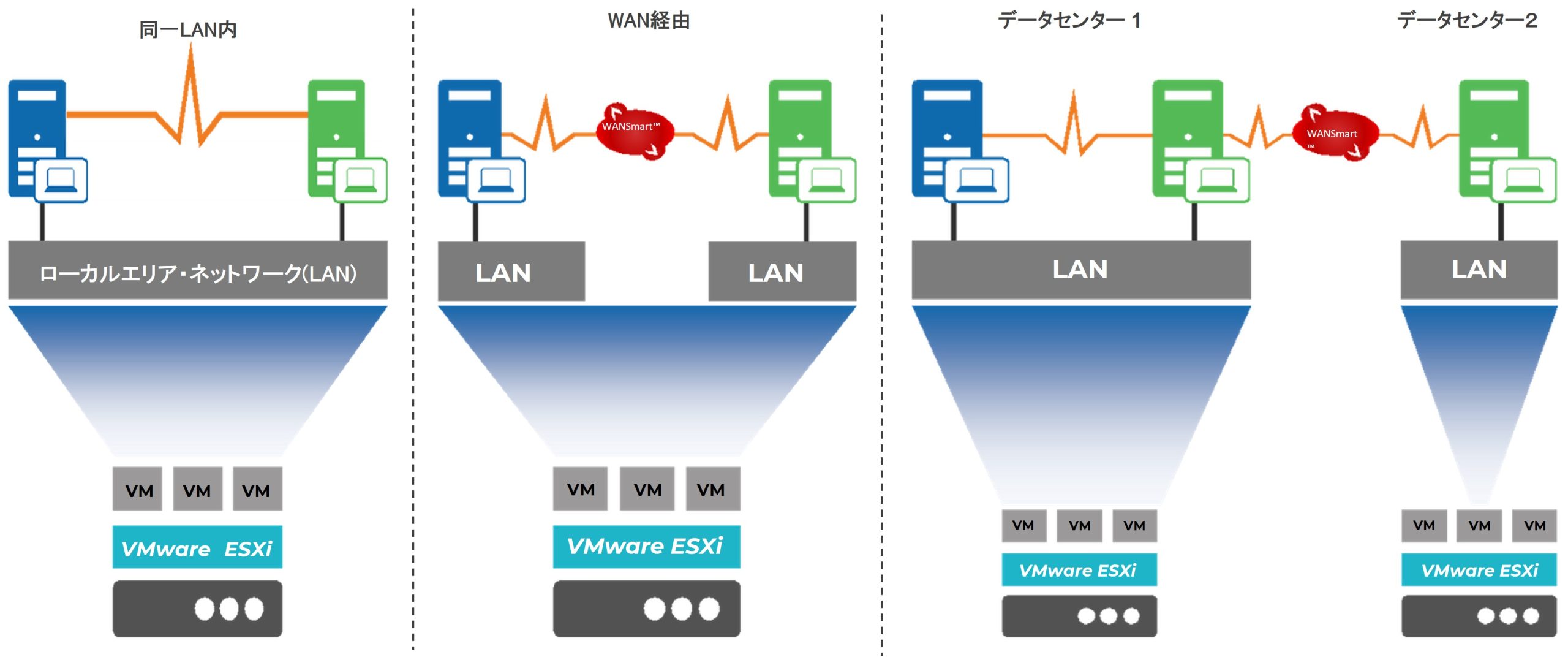
同一LAN上、WAN経由、WAN経由で異なるデータセンターなど柔軟な設置パターン
最近の例では、CEの仕組みは2024年7月に世界中で広範囲な影響を起こしたクラウドストライクの障害時でも、ユーザー企業が問題なく運用を継続できたことでも有効性が確認されました。
ランサムウェアによる暗号化や、人的エラー、ハードウェア障害など、アプリケーションの稼働を脅かす多様な種類のイベントの発生時でも、アプリケーションの継続稼働を確保できるソリューションについて、是非、下記のボタンから詳細もお確かめください。