Kerberoasting検出のためのBeyondTrustの統計モデル
実環境におけるチケット要求パターンのモデリング
BeyondTrustのKerberoasting検出アプローチは、カウントデータ(回数データ)の複雑さに対応するために設計された堅牢な統計フレームワークを活用しています。
このアプローチでは、以下のような複数の課題に同時に対処できる離散確率モデルを使用しています:
- 活動がまれなアカウントに起こりやすいゼロ/ワンの偏り(zero/one inflation)
- 頻度パターンの大きなばらつきに起因する多峰性や歪んだ分布
- 直近の観測結果を重視し、すでに現在の挙動を反映しなくなった過去データの重みを減じる必要性
- 活動頻度が低いながらも分布の裾が重い(heavy-tailed)アカウントにおける、確率推定を洗練させるための潜在クラスタの特定
統計的有意性と実務的有意性のバランス
この手法では、統計的有意性と実務的有意性のしきい値の両方を取り入れることで、計算資源の最適化と調査対象の優先順位付けを実現しています。
たとえば、小規模な組織においては、Kerberosのサービスチケット要求が2件あれば統計的に異常とみなされ、4件であれば極めてまれと判断されることがあります。
とはいえ、単に2件の差があるからといって、調査リソースを割くには及ばない場合もあります。
一方、大規模なエンタープライズ環境では、一部のアカウントが日常的に数百件のチケットリクエストを生成している場合もあります。
そうした環境では、履歴パターンよりも20件多いリクエストが発生したとしても、相対的な増加率が1.1倍程度にとどまるのであれば、許容範囲内の変動とみなされ、エスカレーションの必要はないとされます。
効率的なデータ抽出と処理
モデルの推定にあたっては、スケール(規模)とパフォーマンスの両面を考慮したデータ抽出のアプローチが採用されています。
BeyondTrustのデータサイエンティストは、統計的な精度を確保しつつ、運用環境での計算効率を最大化するため、毎回の実行で処理する履歴データ量を慎重に調整しています。
正確性を高めるための動的更新と値の打ち切り(センサリング)
このモデルアーキテクチャでは、時系列順にデータを処理していく手法を採用しており、各タイムスタンプごとにパラメータを更新して、あらかじめ定義された要件に対応しています。
また、閾値未満の値を除外する「件数のセンサリング(censoring)」も実装しており、これは以下の2つの目的に貢献しています:
- 計算負荷の削減
- 統計的にはまれであっても、実務上は無視してよい少数のカウントが結果に過度な影響を与えないようにする
このセンサリング処理は、確率推定のロジックに直接組み込まれているため、モデル全体として統計的一貫性を維持しています。
非定常性への対応:スライディングウィンドウの活用
前述のとおり、時間の経過とともに行動パターンが変化する非定常性の問題に対処するために、モデルには動的なスライディングウィンドウの仕組みが取り入れられています。
このアプローチにより、直近の頻度変化に対応しながら、数か月に一度しか発生しないような極端なイベントも捉えることができます。
検出制御のためのパーセンタイル利用
本モデルでは、P90、P95、P999といった高位パーセンタイルを、制御手段の中心的な指標として活用しています。
これにより、以下の3つの主要タスクを可能にしています:
- 類似した件数のグループ化
- 判定のためのしきい値設定
- 結果の解釈
たとえば、異常アラートを1か月あたり3件に制限したい場合(1日20時間稼働前提)、99.5パーセンタイル(P995)をリスクの測定値として使用しました。
このようにして、なぜ統計モデリングがこの種の問題に適しているかを実証しています。
従来分布の代替としてのヒストグラム手法
負の二項分布のような従来の統計分布を使う代わりに(これらは非現実的に小さなp値など、誤解を招く結果をもたらす可能性があります)、私たちはより単純なヒストグラム法を選択しました。
ヒストグラムのビンサイズ(区切り幅)は、先ほどの上位パーセンタイルを基準にして決定されました。
このアプローチにより、私たちが名付けた「スライディングウィンドウによるセンサリング付きクラスタリングq統計ヒストグラム」という手法が形成されました。
これは、時間とともに変化するデータを動的に整理・分析するための方法論です。
ヒストグラムクラスタリング手法の仕組み
以下に、私たちのヒストグラム手法の仕組みを簡略に説明します。
ヒストグラムクラスタの構成
仮に、3つの時系列データ Z1(t), Z2(t), Z3(t) があるとします。
それぞれは、個別のアカウントが時間の経過とともに行った Kerberos サービスチケットのリクエスト件数のパターンを表します。
ここでの目的は、これら3つの系列を 2つのクラスタに分類することです。
分類には以下のルールを適用します:
- データ点同士が q統計量で0.95以内
- 値の比率が 1.3倍以内
- 値の差が 3以内
この3条件をすべて満たす場合、2つの系列は「十分に似ている」と見なされ、同じクラスタに属すると判断します。
クラスタリング結果
このルールに基づいてクラスタリングを行った結果、Z1 は クラスタ1 を構成することになります。
なぜなら、Z2 や Z3 のいずれとも、上位パーセンタイルの類似性条件を満たさなかったためです。
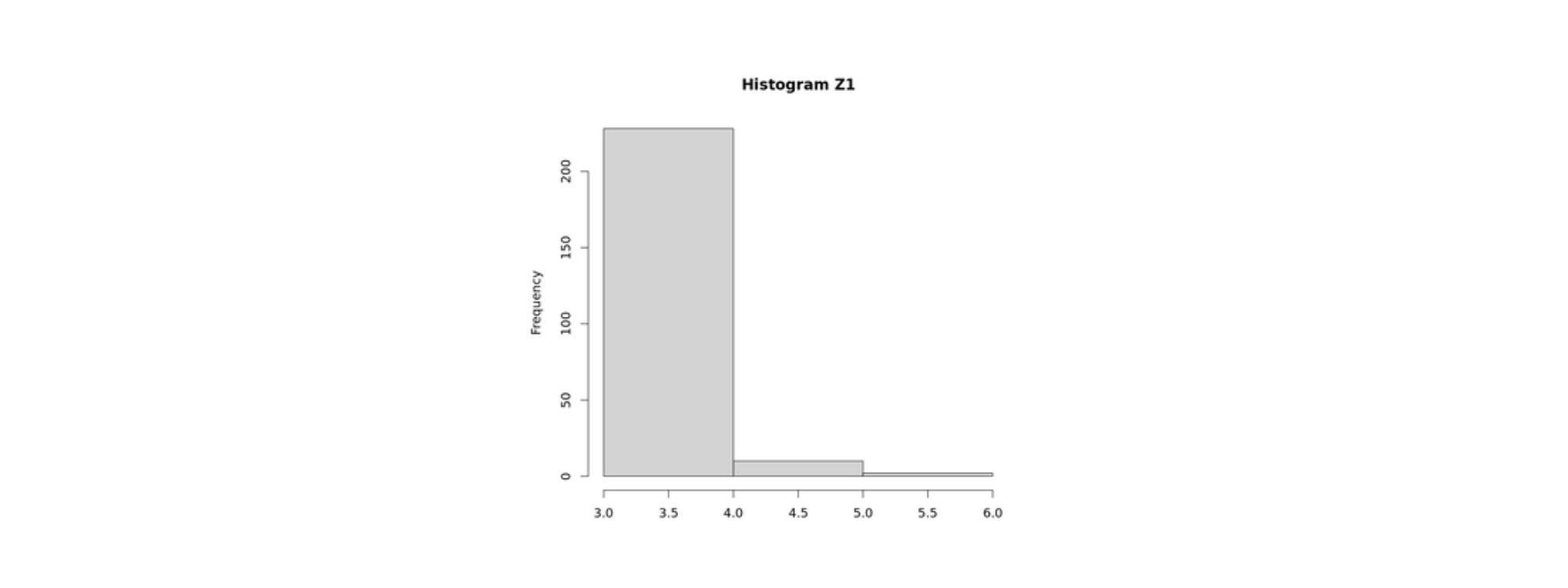
図5:Z1 の時系列データとクラスタ1
Z2 および Z3 は、95パーセンタイル(P95)の値が定義した閾値内に収まっているため、クラスタ2に分類されます。
つまり、これらのアカウントの動作パターンは、互いに「十分に似ている」と見なされ、同一グループとして扱うことができます。
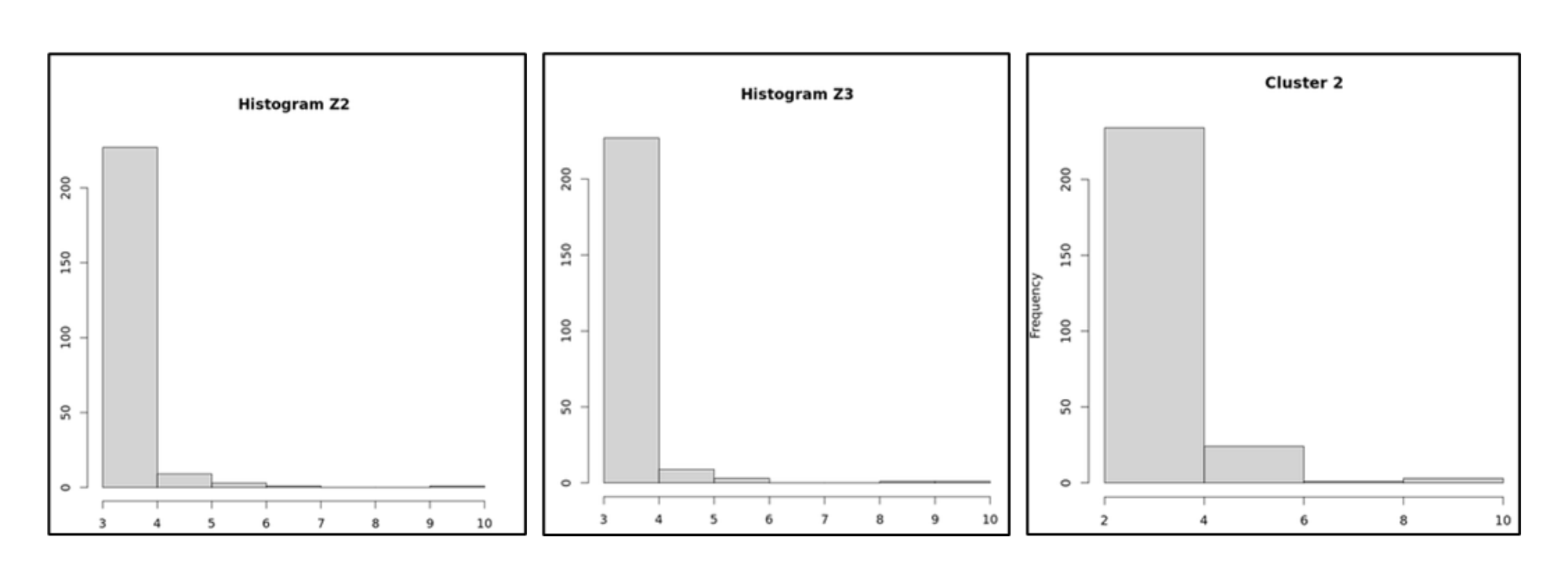
図6:Z2 および Z3 がクラスタ2を構成
異常スコアリングの効果:本物の異常と誤検出の見分け
私たちのスコアリング関数は、以下の式に基づいています:
log10(1 + probability(t) × q-ratio(t)) × qthresh × rel_rank(t)
スコアリング結果の比較:
- クラスタリングあり:
Z2 および Z3 は 正常なクラスタの中での標準的な振る舞いと判断され、異常とは見なされませんでした。
- クラスタリングなし:
同じ Z2 および Z3 に対して、約1.6倍の比率差および 4ユニットの差があったため、異常としてフラグが立てられました。
このように、似たパターンを持つ時系列データをクラスタ化することにより、「クラスタごとの通常状態」をモデルが学習し、単独では怪しく見える挙動も、グループ内では自然とみなされるようになります。
その結果、誤検知(false positives)を大幅に減らすことが可能になるのです。
rel_rank(t): パーセンタイルランクが q レベルの閾値を超えた場合に 1、それ以外は 0 となる バイナリフラグ
qthresh: q統計量が閾値を超えた場合に 1、それ以外は 0 となる バイナリフラグ
Kerberoasting調査の結果
私たちは、50日分のデータを用い、Databricksプラットフォーム上で1時間ごとの演算処理を行いながら、本モデルの精度と計算効率を評価しました。
以下は、いくつかの主要な観点における調査結果の要点です。
1. モデルの性能と効率
クラスタの初期化とSpark SQLによるKerberosサービスチケットリクエストのデータ取得後、本モデルは以下の処理をすべて30秒以内で安定して完了しました:
- ヒストグラムの更新
- クラスタリング処理
- スコア計算
- パーセンタイルランク付け
- 結果の保存
2. 異常検出の成果
1,200件の1時間単位の評価期間にわたり、モデルは以下の条件を満たす6件の異常候補を検出しました:
- 99.5パーセンタイルを超える値
- q-ratio(q統計比率)1.5倍以上
- q-difference(q統計差分)3以上(図7にて視覚的に例示)
これらの異常は、時間的に以下のような顕著なパターンを示していました:
- 特定の短時間に集中する非相関的スパイク
- 分散の増加
- 活動量の一時的な大きな変動
6件のうち、1アカウントが2時間連続で検出されたケースを含めて、3件は以下の追加条件も満たしていました:
- 異なる種類のサービス名(Service Name)が複数含まれていること
このうち2件はペネトレーションテストによるものであり、残る1件は本ブログで実施したKerberoastingの模擬攻撃に対応していました。
残る3件の調査では、いずれもActive Directory内の大規模な変更が原因で、一時的にサービスチケットのリクエストが急増していたことが判明しました。
これらの変化は、アカウント単位および企業全体の通常傾向(ベースライン)を一時的に超えていました。
なお、候補6については、ID管理の観点からさらなる精査が必要と判断されました。
調査の結果、このアカウントが本来意図していた一部のSQLサービスだけでなく、全SQLサービスに対してチケットをリクエストしてしまうという事態が、企業内の設定変更によって偶発的に引き起こされていたことが判明しました。
このように、異常検出の結果からは、本モデルが想定外の活動や構成ミスを高精度で浮き彫りにする能力を有していることが実証されました。
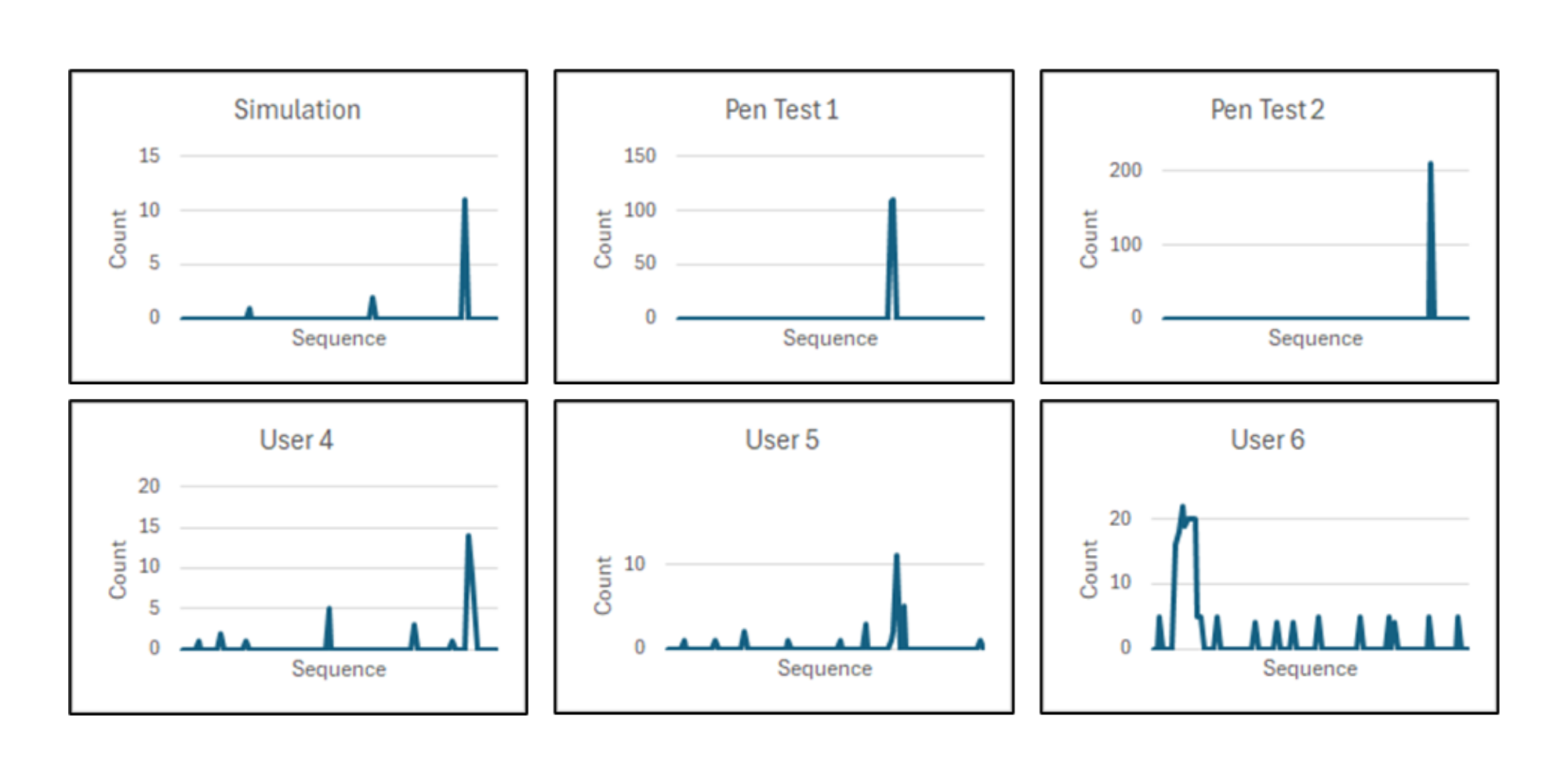
図7:イベント4769における、異常が検出された6名のユーザーに対するサービス名の種類別の1時間ごとのカウント
3. 動的な重み付け調整による外れ値への対応
本モデルは、各クラスタごとの確率を算出する際に用いるスライディングウィンドウを動的に更新しつつ、エンタープライズ全体で異常スコアのパーセンタイル順位も時系列で更新しています。
その結果、極端な値を示すアカウントに対しても、最大2回程度の連続発生があれば、適切にスコアの重み付けを調整(ダウンウェイト)することができました。
通常の異常検出手法では、このような極端値の非定常性に対応するには、より長い時間や複雑な処理が必要となるケースが多く、今回のような即時的な適応は困難です。
4. コンテキストを考慮したフィルタリングによる精度向上
今回の調査結果は、純粋な統計的異常検出手法だけでは限界があることを浮き彫りにしました。
統計的にまれな挙動であっても、必ずしもセキュリティ上の脅威を意味するとは限りません。
真に有効な脅威検出のためには、状況依存のフィルタリングが不可欠です。
BeyondTrustの実装では、次のようなフィルタリングを適用することで、検出精度を高め、ノイズを大幅に削減しました:
-
システムアカウントを除外
-
一定周期で規則的に発生する予測可能なパターン(例:毎時のスパイク)を除外
-
複数のサービス種別を、弱い暗号化方式で要求しているユーザーアカウントを重点的に監視
こうしたコンテキストを踏まえたアプローチにより、検出の「信号対雑音比(S/N比)」を大幅に向上させることができました。
結論
Kerberoastingのようなポスト・エクスプロイト手法に対処するには、単純なシグネチャベースや静的ルールベースの防御だけでは不十分です。こうした攻撃の本質は、正規のプロトコルと動作を悪用する点にあり、結果として検出が非常に困難になります。
本稿で紹介した統計モデルは、以下のような設計上の工夫により、Kerberoastingのような動的かつ文脈依存の攻撃にも対応できることを実証しています:
- ヒストグラムベースのクラスタリングを用いた柔軟なしきい値設計
- コンテキストに基づくフィルタリングによる誤検知の削減
- 非定常性を考慮した動的なスコア調整メカニズム
Kerberosの監視から本質的な脅威を浮かび上がらせるには、単に異常値を探すだけでなく、「何が通常か」を理解した上で、その逸脱を読み解く能力が求められます。BeyondTrustの研究チームは、こうした洞察を支えるモデルを設計・実装し、実データでの有効性を確認しました。
セキュリティの文脈では、「まれであること」は必ずしも「悪意があること」を意味しません。本当に対処すべき脅威に絞り込むには、統計的異常に加えて、環境固有の背景や目的に応じた判断軸が不可欠です。
Identity Security Risk Assessment を無償でお試しください!
Cole Sodja、BeyondTrust社 契約セキュリティ統計アナリスト
Cole Sodjaは、BeyondTrustの契約セキュリティ統計アナリストであり、Amazon、Microsoft、Securonixといった大手テクノロジー企業で20年以上にわたり応用統計に携わってきた実績を持ちます。特に時系列解析を専門とし、自身の専門分野を「確率的な脅威ハンティングとインテリジェンス」と定義。エンティティのプロファイリング、シグナルと異常の統合、重要インシデントのランキング化を通じて、実践的なセキュリティ分析を推進しています。予測分析、変化点検出、行動監視における深い知見を活かし、BeyondTrustの異常検知機能の強化に貢献しています。
Christopher Calvani、BeyondTrust社 アソシエイト・セキュリティリサーチャー
Christopher Calvaniは、BeyondTrustのセキュリティリサーチチームに所属する研究員であり、脆弱性リサーチと検知エンジニアリングを融合させたアプローチで、顧客の脅威対策支援に取り組んでいます。ロチェスター工科大学にてサイバーセキュリティ学の理学士号を取得。過去には、Fidelity Investmentsにてシステムエンジニアのインターンとして大規模インフラ運用を支援したほか、StavvyではDevSecOpsの高度化にも携わりました。
Phantom Labs™(BeyondTrustリサーチ部門)
Phantom Labs™ は、BeyondTrustのリサーチ専門チームです。私たちは、サイバー脅威を深く理解するためには、顧客やパートナーと緊密に連携しながら、実際の攻撃手法に基づいた研究を行うことが不可欠であると考えています。
脅威アクターによる新たな攻撃手法やエクスプロイト技術を詳細に分析するとともに、独自の調査研究も実施。アイデンティティを標的とした脅威への防御力を高めるための支援を使命としています。