
2024年に入って以降、大きく二つの要因で弊社のお客様を含むITユーザー企業での災害対策の見直しが見られます。
一つ目は今年の年始に発生した能登半島地震の影響で、公共のシステムやデータセンターへの続報を受けてのことです。二つ目は、長年仮想環境のプラットフォームの主流であった米VMware社が米Broadcom社に買収されたことからの影響が見えはじめるにつれ、世界的に見直しの機運が生じていることによります。
一層重視されるシステムの継続利用と直近の災害で見えた課題
一点目の能登半島地震後の影響は、弊社が東方通信社月刊コロンブス誌とタイアップで情報セキュリティ関連の話題を連載で発信している記事に要約されています。
「災害時にもシステムを稼働させつづけるコンティニュイティーエンジンに注目!!」より
2024年1月に発生した能登半島地震。石川県内では6月18日の時点で災害関連死を含む282人の死亡が確認されているほか、住宅への被害は8万918棟(全壊は8,180棟)に達している。しかも、今後もマグニチュード6以上の地震が発生する可能性が示されるなど、まだまだ予断を許さない状況がつづいている。そこで、今号では災害時の情報システムの継続利用と対策について考えてみたい。
能登半島地震で浮き彫りになった課題
能登半島地震においては、人や建物だけでなく、情報システムに関しても多数の被害やトラブルが報告された。たとえば、この地震では石川県内の一部の自治体でネットワークが一時利用できなくなったという。首都直下地震などが懸念されるなか、自治体、そして中央省庁のネットワークは大丈夫なのだろうか。そのほか、想定外の渋滞によって、データセンターの職員が到着までに必要以上に時間を要してしまったといった課題も浮き彫りになったし、石川県志賀町ではデータセンターのサービスが一時的に停止して、復旧まで丸二日を要したという。
ITが社会インフラとなっている今日、災害時においてもその継続的な利用は不可欠。そのことを実感している企業も増えており、ITR(日本のリサーチ会社)によると、IT戦略でシステムレジリエンス(可用性・信頼性の強化)の優先度が高いとしている企業は79%に達しているとのこと。その理由としては「デジタル化によって業務のITシステムへの依存が高まっている(38%)」「システムのダウンタイムによる損失が大きくなっている(31%)」「24時間止められないビジネスやサービスが増えている(31%)」「地震などの予期せぬ自然災害が増えている(23%)」などがあげられている。
こうした声に対し、長年、サイバーセキュリティとシステム運用支援に携わってきた㈱ブロード(東京都千代田区)は「バックアップさえとっておけば、いざというときに復旧できると考える人もいるが、実際には災害対策用のシステムを用意している場合ですら、元の稼働状態に戻すまでに少なくとも数時間、多くの場合は数日単位の時間を要している」と解説する。しかも「システムは日々データが増えるなど刻々と変動しつづけているので、バックアップ環境を構築して、リアルタイムに同じ状態を維持する仕組みをつくりあげるには膨大な費用が生じる」と指摘する。
実際、多くの企業がレジリエンス、つまり継続利用に多様な課題を感じており、前述のITRの調査においても「ツールやソリューションにかかるコストの負担が大きい(36%)」「知識やスキルを持った人材が不足している(29%)」「システムの状態に関する可視化ができていない(27%)」「復旧などレジリエンスのための運用が属人的で自動化されていない(26%)」といった声があがっている。
出典 東方通信社 月刊「コロンブス」2024年7月号 掲載記事より(記事全文はこちら)
見直しされるVMwareの機構をいかした災害復旧対策
多くの企業で利用される仮想サーバーをホストするVMware社の仮想化ソリューションは、主軸であるハイパーバイザーと複数のハイパーバイザーを集中管理するvCenterを使い、高可用性を実現する仕組みで人気を博してきました。
複数のゲストOS(仮想サーバー)を稼働させるハイパーバイザーに異変が生じた場合、vCenterの制御で別のハイパーバイザーに仮想サーバーの稼働を移転し、継続使用することが可能です。
日本国内でもVMwareの普及に伴い、vCenterを活用してシステムの冗長化を図るユーザー企業は少なくありません。
しかし、近年の米Broadcom社によるVMware社の買収後の影響に注目が集まる中、引き続き、この仕組みに頼るのが妥当かどうかを見直しする動きが国内外で見られます。
一つ目に、買収後のライセンス価格体系が見直され、契約内容によっては従来よりも高額になるとの情報が広まり始めており、例えば弊社のお客様でもこれに当てはまるとのお話を複数伺いました。
二つ目に業務アプリケーションの継続利用の観点では、幾つかの留意点があり、それを懸念する複数のユーザー企業からもご相談をいただいています。
当社に寄せられた情報を基に、これらの留意点を要約してみます。
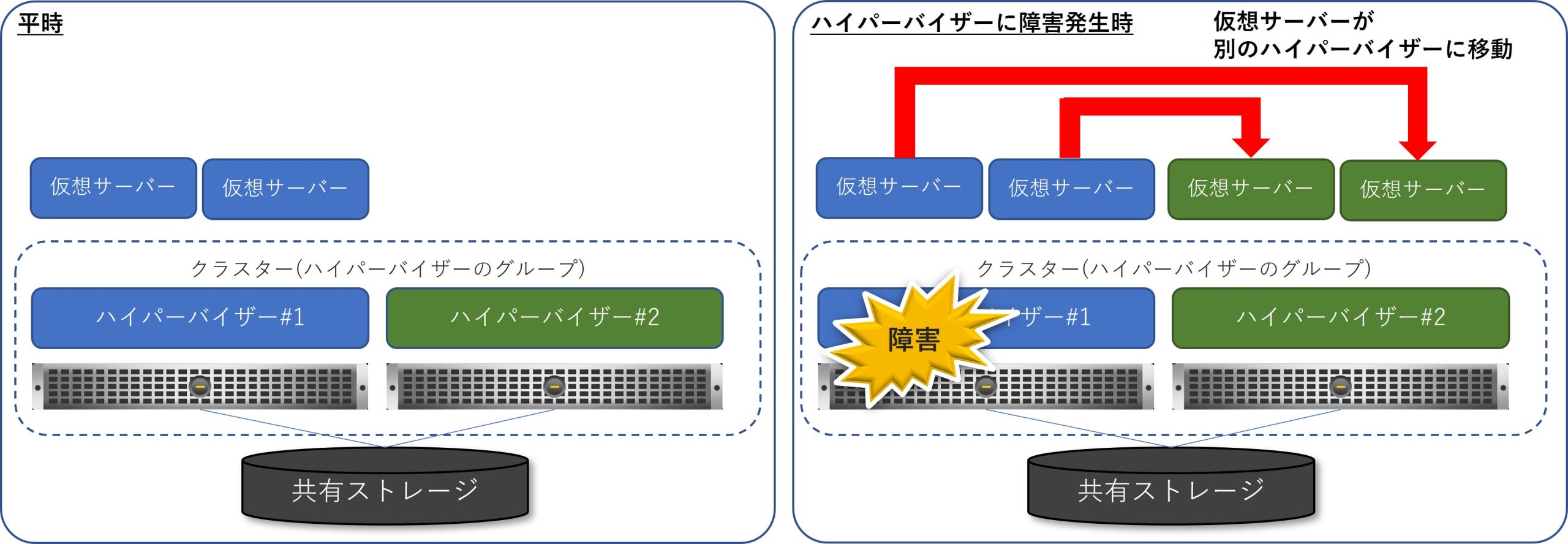
VMwareのHA (High Availability)機構
- HAは、ハイパーバイザーが稼働する物理マシンの障害発生時に、クラスター内(vCenterで管理するグループ内)の別のハイパーバイザーで稼働させる仕組み
- 稼働を移動する先のハイパーバイザーでは切り替え時のみ仮想サーバーのリソース(CPUやメモリー)を割り当てし、HA機構のための追加のディスクリソースは不要
- 障害が発生したハイパーバイザーで稼働する全ての仮想サーバーが、移動先のハイパーバイザーでOSの起動処理に入るので、稼働再開までには数分を要する
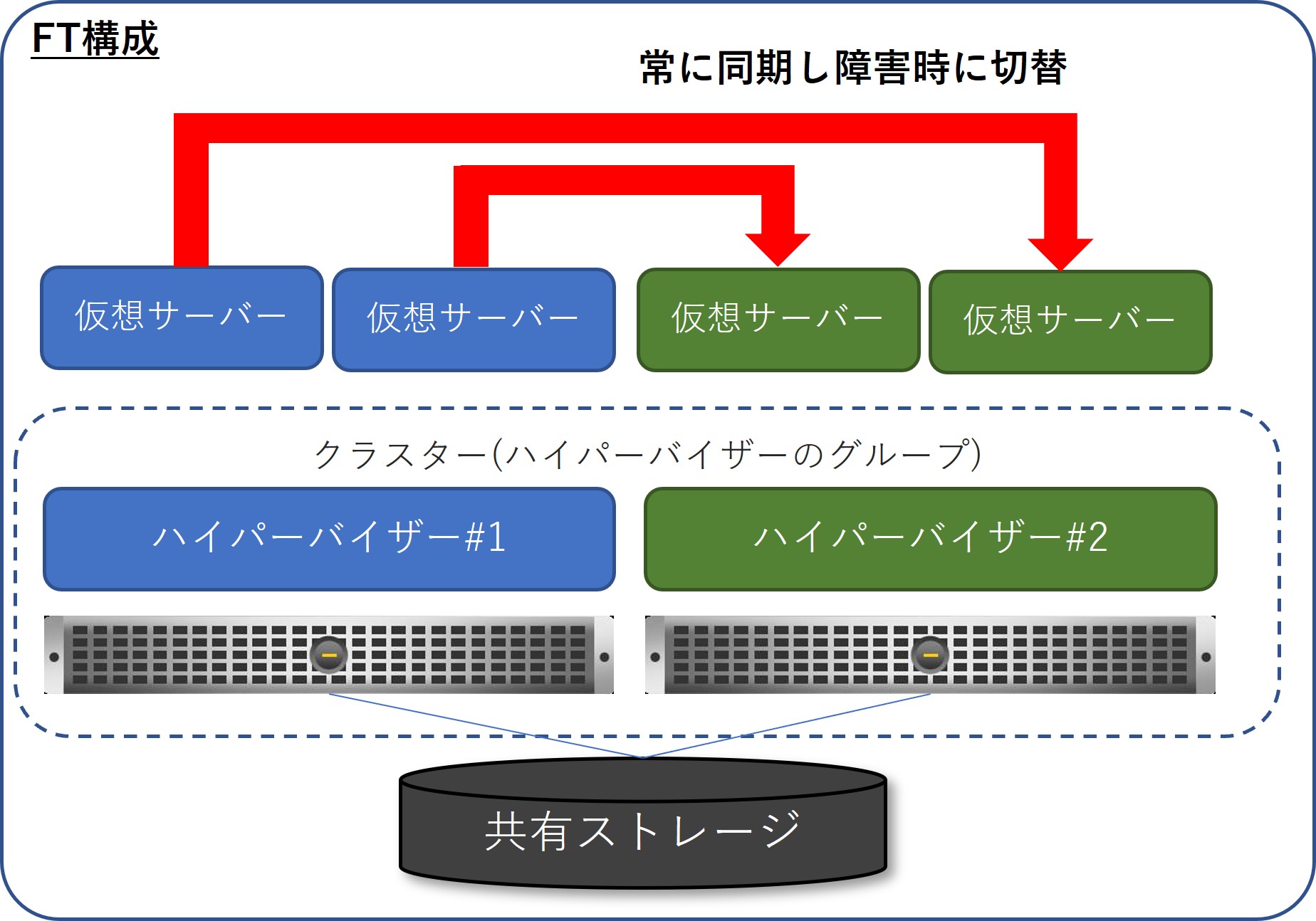
VMwareのFT (Fault Tolerance)機構
- HAとの大きな違いは、稼働中の仮想マシンをプライマリとして、セカンダリに該当する仮想マシンをクラスター内の別のハイパーバイザーでホットスタンバイさせる点
- これにより、障害発生時でもサービス停止殆どなしで稼働を切替可能
- ホットスタンバイ用のリソースが必要であり、セカンダリが動作するハイパーバイザーの負荷に加えて、FT設定間のネットワークの帯域要件や、仮想CPU数の制限、スナップショットは未サポートであること等に留意が必要
VMWareのHAとFTに共通する留意点
- HAはハイパーバイザーの障害をトリガーとして動作し、FTはこれに加えて仮想サーバーのOS障害にも対応するが、これらの機能はアプリケーションの障害や異常には対応しない
- HAやFTを動作させる複数のハイパーバイザーが単一の共有ストレージに依存する場合、冗長化の有効性はこのストレージの不具合に大きく依存する
災害対策に向けた別の選択肢
VMwareのライセンス体系の変更により、特にvCenterの費用が上がってしまうケースを複数のお客様からお聞きしています。
vCenterは、複数のハイパーバイザーを管理し制御するVMwareシステムの中心的な役割を担いますが、HAやFTなどの冗長化を主な用途として導入している場合、別の選択肢も考えられます。
例えばNeverFail社のNeverfail Continuity Engine(CE)は、アプリケーションの継続的な可用性の実現を目的としたソリューションですが、次のことを実現できます。
- 対象サーバーのOS環境はもちろん、アプリケーションサービスのレベルの障害に反応して自動切替
- 数十秒で完璧な精度のスイッチオーバ/フェイルオーバを実現
- 物理、仮想、クラウド等、多様な組み合わせに対応
- 問題解決後のスイッチバック/フェイルバックも容易に実現
今回は、年初の大震災の影響や、日本でも広く利用されるVMwareの機構を使った冗長化について取り上げました。
最後にご紹介したNeverfailについては、下記のリンクをぜひクリックしてみてください。