
3日かかったCrowdStrike Falcon Sensor障害の修正
既に多く報じられていますが、さる7月19日、世界中のIT担当者を驚かせた重大な障害が発生しました。米国クラウドストライク社のセキュリティソリューション、CrowdStrike Falcon Endpoint Protection の更新が原因で、Windowsデバイスにおいてシステムクラッシュが広範に発生した件です。
この障害は、同社の CrowdStrike Falcon Endpoint Protection に含まれる Falcon Sensor の更新モジュールに不具合が生じたことで発生しました。その結果、Windows OSが正常に動作しなくなり、『ブルースクリーン(BSOD)』と呼ばれる画面が表示され、システムが停止しました。
このソリューションは、デスクトップ版とサーバー版の両方をサポートしており、世界中の多くの企業や個人ユーザーに利用されています。更新が反映されたWindowsデバイスは次々とクラッシュし、その影響は世界中で約850万台のデバイスに及びました*1。
この障害は、特定の条件(適用タイミング、Windowsバージョン、システム設定など)に合致した場合にのみ発生しました*2。そのため、ユーザーからの報告や連絡に基づく調査において、発生原因の見極めには時間がかかり、その結果として解消方法や正式な情報発信にも日数を要しました*3。その間にも多くのITシステムに深刻な影響を与え、影響が広がり続けました。
クラウドストライクおよびマイクロソフトは、問題が発生してから3日後の7月22日に正式な対処方法を発表しましたが、それまでの間、多くのシステムが停止状態にありました。この間、システムの復旧には再起動やセーフモードの使用が必要で、一部ではBitLockerの回復キー入力が求められるなど*4、IT担当者にとって大きな負担となりました。
ITシステムのレジリエンシーを改めて考える
先だって、日本の災害の特徴の一つ、震災を起点とした災害対策について取り上げましたが、今回、クラウドストライクの障害を取り上げた理由は、ソフトウェア製品の不具合一つでシステムが停止し、その復旧には製品ベンダーによる改修策だけで3日を要するといった事態も起こりえる、という点を重視してのことです。
システムのレジリエンシー(回復力)について改めて考えてみたいと思います。
レジリエンシーとは、システムが予期しない障害やサイバー攻撃に直面した際、その影響を最小限に抑え、迅速かつ効果的に回復する能力を指します。具体的には、システムがどれだけ迅速に正常な状態に戻れるか、また将来の問題を予防するためにどの程度の対策が講じられているかが重要です。
レジリエンシーの高いシステムは、組織にとっていくつかの重要な事業や業務上の利点をもたらします。
- システムのダウンタイムを短縮することで、ビジネスの中断を防ぎ、結果として大きなコスト削減に繋がります。
- 信頼性の高いシステムは顧客からの信頼を築き、競争が激化する市場においても優位性を保つことができます。
- 強力なレジリエンシーを持つ企業は、リスク管理がしっかりしていると見なされ、規制対応やコンプライアンスの面でもメリットを享受することができます。
また、レジリエンシーは単に問題が発生したときに迅速に対応するだけではなく、システム設計の段階から多様性や冗長性を取り入れ、様々なリスクに対して柔軟に対応できる構造を持つことが求められます。たとえば、複数のデータセンターやクラウド環境を活用して、障害が発生した際に瞬時に切り替えられる仕組みを構築することも効果的です。
クラウドストライクの障害も難なく乗り切った、先進的な継続的アプリケーション可用性向上のソリューションとは
クラウドストライクの障害は、ソフトウェア製品の更新の不具合が、OSの稼働環境に悪影響し、OS自体が正常に稼働できなくなった例の一つと言えます。
専門的なソフトウェア開発会社の品質管理プロセスを経てもなお、発生してしまったクラウドストライクの障害はむしろレアケースとも言えるかも知れませんが、システムが利用停止に追い込まれる事態を引き起こしえる要因は、実際には他にも多数あります。
例えば:

こうした障害の発生の備えて、伝統的にバックアップとレストアという方法を基本に、データのレプリケーション(同期)や、現在主流の仮想環境プラットフォームで提供される冗長化やフェイルオーバーの仕組みが使われるようになりました。
しかし課題がいくつか残ります。
- 従来のフェイルオーバーの仕組みはOSレベルの不具合をトリガーとして動作するが、もしアプリケーションレベルでクラウドストライクの障害と同様の事態が起きたら対応できるか?
- 停止が許されない業務アプリケーションの復旧が、何時間、何日もかかっていいのか?
- アプリケーション単位で確実な継続稼働を実現したいが、その設計・構築にかける予算もナレッジも足りない!
これまで出来そうで出来なかった、アプリケーションレベルでの高可用性の達成を、この分野の先進的でシンプルなソリューションで実現できる時代になりました。
下図は、障害対策として取られてきた手法の中、で、アプリケーションレベルでの高可用性の位置づけを概念図で表しています。
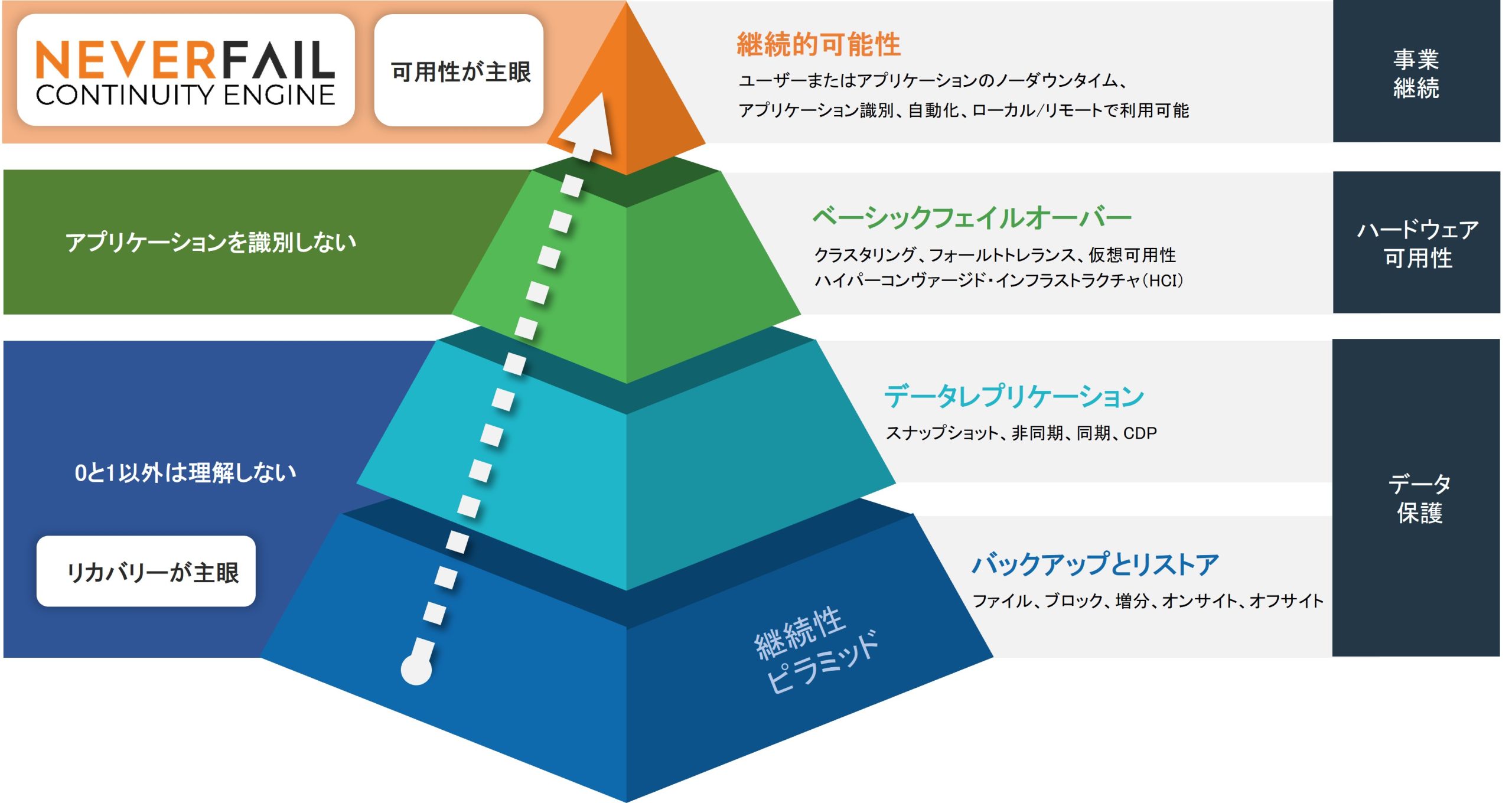
古典的なバックアップとレストアから進化している継続性向上の仕組み
例えばNeverFail社のNeverfail Continuity Engine(CE)は、アプリケーションの継続的な可用性の実現を目的としたソリューションですが、次のことを実現できます。
- 対象サーバーのOS環境はもちろん、アプリケーションサービスのレベルの障害に反応して自動切替
- 数十秒で完璧な精度のスイッチオーバ/フェイルオーバを実現
- 物理、仮想、クラウド等、多様な組み合わせに対応
- 問題解決後のスイッチバック/フェイルバックも容易に実現
今回取り上げたシステムの利用停止、さらに言えば、アプリケーションの利用停止を回避できるソリューションであり、そのユーザー企業はクラウドストライクの障害の際も難なく運用を続けることができました。
これらの企業は、災害や障害に対応する範囲の要件に応じてCEが対応する多様な設置パターンで、アプリケーションの継続可用性を確保しています。
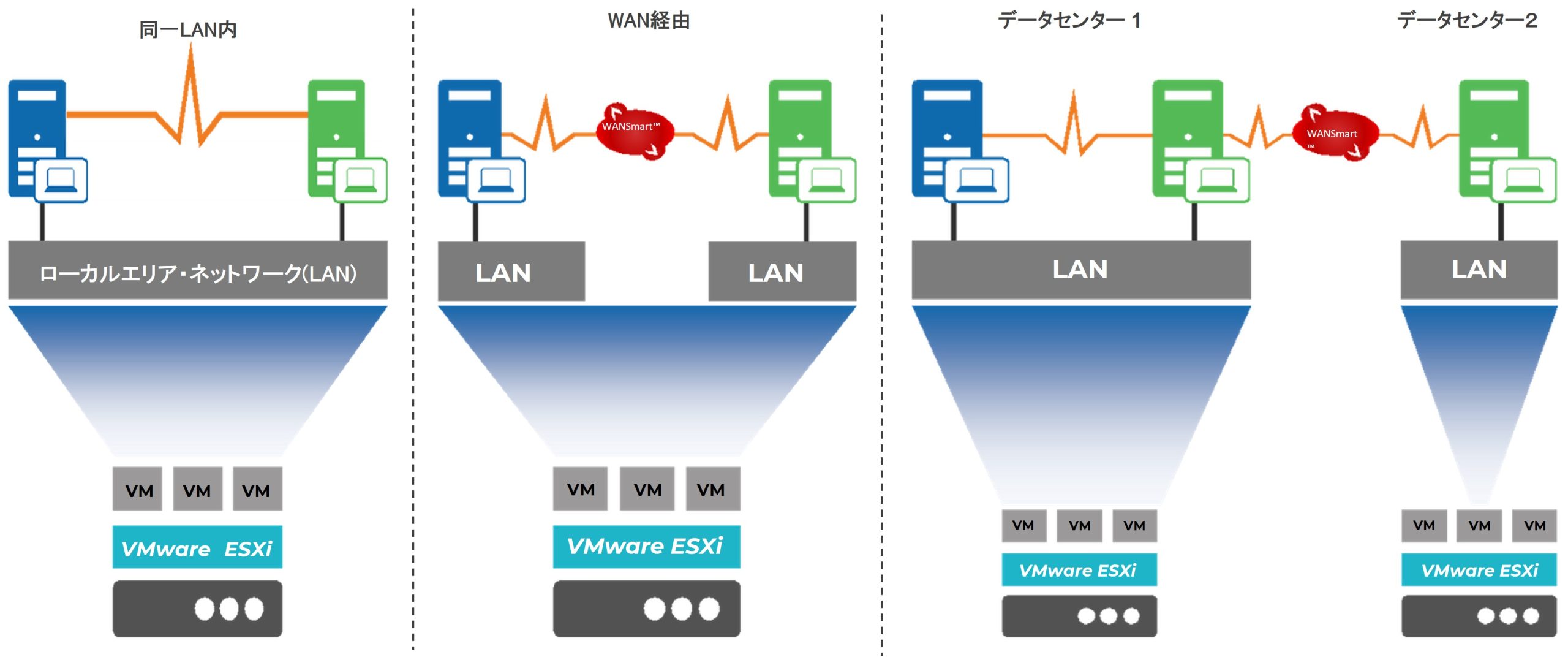
同一LAN上、WAN経由、WAN経由で異なるデータセンターなど柔軟な設置パターン
クラウドストライクの障害のケースは発生から3日後に対処方法が発表されましたが、当然ながら、障害発生時点では三日後に対処方法が発表される予定といった情報があるわけもなく、多くのユーザー企業の担当者は、修正見込みもわからない中で判断に迷われたことでしょう。
多くの企業が対処に苦慮するこうした混乱の中、Neverfailのユーザー企業は、こういったアプリケーションの更新を本番サーバに適用して稼働確認をする間に、セカンダリにプライマリの役割を移し、そのままビジネスシステムを継続でき、問題を未然に防止することができました。また、万が一障害があっても即座なフェイルオーバーで、セカンダリがプライマリとしてビジネスを継続できたのです。
出典 出典・参照情報
*1 Wikipedia – 2024 CrowdStrike Incident
*2 CrowdStrike Content Update Remediation Hub
*3 CrowdStrike Content Update Remediation Hub
*4 Microsoft Tech Community – New Recovery Tool